

一、概况
NVIDIA A30 TENSOR CORE GPU
适用于不同企业的 AI 推理和主流计算 NVIDIA A30 Tensor Core GPU 是用途广泛的主流计算 GPU, 适用于 AI 推理和主流企业工作负载。这款 GPU 采用 NVIDIA Ampere 架构的 Tensor Core 技术,支持广泛的数学精度, 可针对每个工作负载提供单个加速器。 专为大规模 AI 推理而构建的同一计算资源能够通过 TF32 精度快速重新训练 AI 模型,同时还能借助 FP64 Tensor Core 加速高性能计算(HPC)应用。多实例 GPU (MIG)及 FP64 Tensor Core,可在 165W 低功率电路下相结合,实现速度 高达 933GB/s 的显存带宽,以上特性均在这一适用于主流 服务器的 PCIe 卡上体现。 通过结合使用第三代 Tensor Core 与 MIG 技术,其可在各种 工作负载中提供安全的服务质量,所有这些技术都由多功能 GPU 提供支持,从而实现弹性数据中心。A30 在各个规模的 工作负载中都具有多用途计算能力,能够尽可能地为主流 企业创造价值。 A30 是整个 NVIDIA 数据中心解决方案的一部分,该解决方案 由硬件、网络、软件、库以及 NGC? 中经优化的 AI 模型和 应用等构成。作为性能超强的端到端数据中心专用 AI 和 HPC 平台,A30 可助力研究人员交付真实结果,并将解决方案 大规模部署到生产环境中。

二、特性
二、特性
>>NVIDIA AMPERE 架构
无论是使用 MIG 技术将 A30GPU 分割为较小的实例,还是使用 NVIDIA NVLink 连接多个GPU 以加速更大规模的工作负载,A30 均可轻松满足多种规模的加速需求,从小型作业到大型多节点工作负载都无一例外。A30 功能全面,这意味着 IT 经理可借此在主流服务器上充分利用数据中心内的每个 GPU,昼夜不停歇。
>>第三代 TENSOR CORE技术
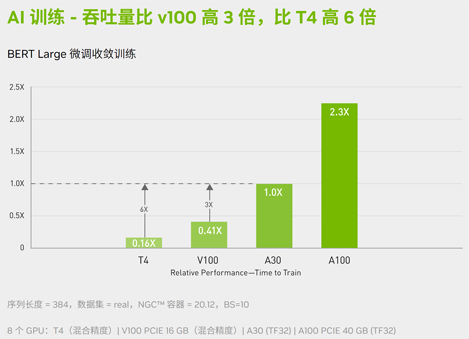
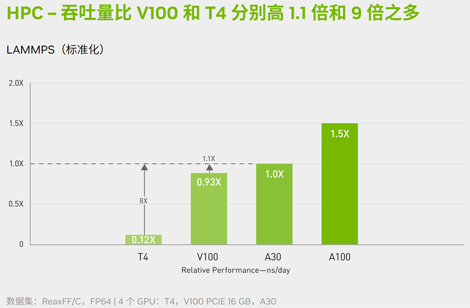
NVIDIA A30 可提供 165 teraFLOPS (TFLOPS)的TF32 精度深度学习性能。相较于 NVIDIA T4 Tensor Core GPU,A30 可将 AI 训练吞吐量提高 20 倍,并将推理性能提高 5 倍以上。A30 可在 HPC 方面提供 10.3 TFLOPS 的 性能,比 NVIDIA V100 Tensor Core GPU 高出了近 30%。
>>新一代 NVLINK
A30 中采用的 NVIDIA NVLink 可提供两倍于上一代的吞吐量。两个 A30 PCIe GPU 可通过 NVLink 桥接器连接,以提供 330 TFLOPS的深度学习性能。
>>多实例 GPU (MIG)
每个 A30 GPU 最多可分割为四个GPU 实例,这些实例在硬件级别完全独立,并各自拥有高带宽显存、缓存和计算核心。借助 MIG,开发者可为其所有应用实现惊人加速。IT 管理员可为每个作业提供符合其规模的 GPU 加速,进而优化利用率,并让每个用户和应用都能享受 GPU 加速性能。
>>HBM2 显存
配合高达 24GB 的高带宽显存(HBM2),A30 可提供933GB/s 的 GPU 显存带宽,适用于主流服务器中的多种 AI 和 HPC 工作负载。
>>结构化稀疏
AI 网络拥有数百万至数十亿个参数。实现准确预测并非要使用所有参数,而且我们还可将某些参数转换为零,以在无损准确性的前提下使模型变得“稀疏”。A30 中的 Tensor Core可为稀疏模型提供高达两倍的性能提升。稀疏功能不仅更易使 AI 理受益,同时还能提升模型训练的性能。
三、NVIDIA A30 应用场景
面向现代 IT 的数据中心解决方案
NVIDIA A30 Tensor Core GPU 采用现代数据中心的核心—— NVIDIA Ampere 架构,是 NVIDIA 数据中心平台不可或缺的一部分。该平台专为深度学习、HPC 及数据分析而构建,并为包括各大深度学习框架在内的 2000 余款应用提供加速。此外,NVIDIA AI Enterprise 是一套端到端云原生 AI 和数据分析软件套件,经认证可在 A30 上运行,适用于结合 VMware vSphere 的基于 hypervisor 的虚拟基础架构。这使您能够在混合云环境中管理和扩展 AI 工作负载。从数据中心到边缘节点均可使用完善的 NVIDIA 平台,不仅能显著提升性能,还能创造众多成本节约机会。
NVIDIA A30 Tensor Core GPU 采用现代数据中心的核心—— NVIDIA Ampere 架构,是 NVIDIA 数据中心平台不可或缺的一部分。该平台专为深度学习、HPC 及数据分析而构建,并为包括各大深度学习框架在内的 2000 余款应用提供加速。此外,NVIDIA AI Enterprise 是一套端到端云原生 AI 和数据分析软件套件,经认证可在 A30 上运行,适用于结合 VMware vSphere 的基于 hypervisor 的虚拟基础架构。这使您能够在混合云环境中管理和扩展 AI 工作负载。从数据中心到边缘节点均可使用完善的 NVIDIA 平台,不仅能显著提升性能,还能创造众多成本节约机会。
>>深度学习训练
为应对对话式 AI 等新型挑战而训练 AI 模型需要强大的计算能力与可扩展性。NVIDIA A30 Tensor Core 具备 Tensor Float (TF32) 精度,可提供比 NVIDIA T4 高 10 倍之多的性能,并且无需更改代码;若使用自动混合精度和 FP16,性能可进一步提升 2 倍,综合起来可将吞吐量提高 20 倍。与 NVIDIA? NVLink?、PCIe Gen4、NVIDIA Mellanox? 网络和 NVIDIA Magnum IO? SDK 配合使用时,可以扩展到数千个 GPU。
Tensor Core 和 MIG 使 A30 全天都能够动态地用于工作负载。它可以在需求高峰时段用于生产推理,并且部分 GPU 可以在非高峰时段改用于快速重新训练同一批模型。
NVIDIA 在行业级 AI 训练基准测试 MLPerf 中取得多项性能佳绩。
>>深度学习推理
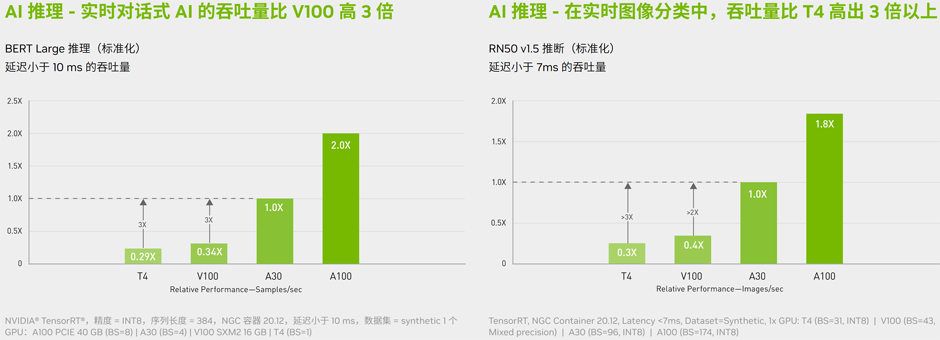
A30 引入了突破性的功能来优化推理工作负载。它能在从 FP64 到 TF32 和 INT4 的整个精度范围内进行加速。A30 每个 GPU 支持多达 4 个 MIG,允许多个网络在安全的硬件分区中同时运行,同时保证服务质量 (QoS)。在 A30 其他推理性能增益的基础之上,仅结构化稀疏支持一项就能带来高达两倍的性能提升。
NVIDIA 产品的出色 AI 性能在 MLPerf 推理测试中得到验证。通过与可以轻松地大规模部署 AI 的 NVIDIA Triton? 推理服务器配合使用,A30 能为不同企业带来此突破性性能.
>>高性能计算
为了获得新一代的发现成果,科学家们希望通过模拟方式来更好地了解我们周围的世界。
NVIDIA A30 采用 FP64 NVIDIA Ampere 架构 Tensor Core,提供自 GPU 推出以来幅度非常大的 HPC 性能飞跃。配合 24 GB 的 GPU 显存和 933 GB/s 的带宽,可让研究人员快速解决双精度计算问题。HPC 应用程序还可以利用 TF32 提高单精度、密集矩阵乘法运算的吞吐量。
FP64 Tensor Core 与 MIG 的结合能让科研机构安全地对 GPU 进行分区,以允许多位研究人员访问计算资源,同时确保 QoS 和更高的 GPU 利用率。部署 AI 的企业可以在需求高峰时段使用 A30 的推理功能,然后在非高峰时段将同一批计算服务器改用于处理 HPC 和 AI 训练工作负载。
>>高性能数据分析
数据科学家需要能够分析和可视化庞大的数据集,并将其转化为宝贵见解。但是,由于数据集分散在多台服务器上,横向扩展解决方案往往会陷入困境。
搭载 A30 的加速服务器可以提供必需的计算能力,并能利用大容量 HBM2 显存、933 GB/s 的显存带宽和通过 NVLink 实现的可扩展性妥善处理这些工作负载。通过结合 InfiniBand、NVIDIA Magnum IO 和 RAPIDS? 开源库套件(包括 RAPIDS Accelerator for Apache Spark),NVIDIA 数据中心平台能够加速这些大型工作负载,并实现超高的性能和效率水平。
>>企业就绪,高效利用
A30 结合 MIG 技术可以更大限度地提高 GPU 加速的基础设施的利用率。借助 MIG,A30 GPU 可划分为多达 4 个独立实例,让多个用户都能使用 GPU 加速功能。
MIG 与 Kubernetes、容器和基于 Hypervisor 的服务器虚拟化配合使用。MIG 可让基础设施管理者为每项作业提供大小合适的 GPU,同时确保 QoS,从而扩大加速计算资源的影响范围,以覆盖每位用户。

四、规格参数
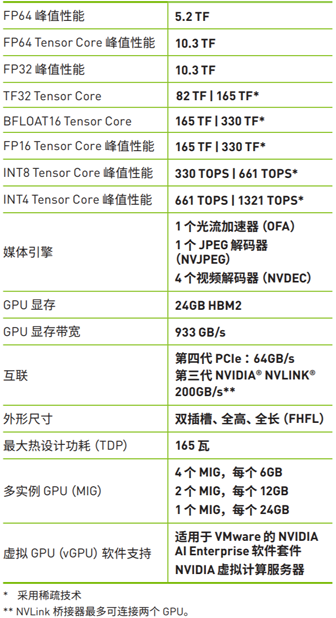
四、规格参数



